# Identifizierung von Dekarbonisierungsversprechen mittels LLM's
## Projektübersicht
Diese Bachelorarbeit untersucht den Einsatz moderner **Large Language Models (LLM's)** zur Identifikation freiwilliger Dekarbonisierungsversprechen von Unternehmen anhand von US-amerikanischen Wirtschafts-Nachrichtenartikeln (2005–2023). Ziel ist es, mittels automatisierter Klassifikation Unterschiede in der semantischen Leistungsfähigkeit und Präzision verschiedener LLMs herauszuarbeiten.
Die Arbeit entstand im Kontext eines laufenden Forschungsprojekts unter der Betreuung von **Prof. Dr. Ole Wilms (Universität Hamburg)** und basiert auf einer Submenge des Datensatzes [Corporate Green Pledges von Bauer et al. (2024)](http://dx.doi.org/10.2139/ssrn.5027881 "Corporate Green Pledges von Bauer et al. (2024)").
## Genutzte Technologien & Tools
- **Python** – Datenanalyse, Modell-Setup, Auswertung
- **Transformermodelle (LLMs)** – Gemma 2, Llama 3.1, ClimateBERT-NetZero, GPT-4
- **Huggingface / Ollama** – für Zugriff auf und Arbeit mit spezialisierten Modellen
- **TikZ / Matplotlib** – Visualisierung der Klassifikationsergebnisse
- **Pandas / NumPy** – Datenmanagement
- **Scikit-learn** – Metriken & Konfusionsmatrix
- **tqdm** - Messung von Zeitspannen der Klassifikationsschleifen
## Projektstruktur
```bash
.
├── data/ # Datensatz-Ausschnitt mit 1000 Artikeln (nur auf Anfrage)
├── src/ # Python-Code zur Vorverarbeitung, Modellanbindung, Klassifikation
├── models/ # LLM-Konfigurationen und Aufrufe (Huggingface, Ollama, API)
├── results/ # Grafiken, Metriken, Konfusionsmatrizen
├── Bachelorarbeit.pdf # Offizielles PDF der Abschlussarbeit
└── README.md
```
## Kern-Features & Erkenntnisse
- **LLM-Komparative Analyse**:
- Vergleich von GPT-4 mit offenen Modellen wie *Gemma 2*, *Llama 3.1* und *ClimateBERT-NetZero*
- Fokus auf **semantisches Verständnis**, **klassifikatorische Präzision** und **promptbasierte Optimierung**
- **Klassifikationsmetrik**:
- Accuracy, Precision, Recall & F1-Score
- Konfusionsmatrizen zur Validierung gegen Human-Coding
- **Prompt Engineering**:
- Vergleich des Originalprompts aus der Forschungsarbeit mit angepassten Prompt-Varianten
- Nachweis einer messbaren **Verbesserung der Klassifikationsgüte** durch gezielte Promptanpassung
## Genutzte Modelle & Quellen
- 🔗 [Gemma 2](https://ollama.com/library/gemma2)
- 🔗 [Llama 3.1](https://ollama.com/library/llama3.1)
- 🔗 [ClimateBERT-NetZero](https://huggingface.co/climatebert/netzero-reduction)
- 🔗 GPT-4 (Closed Source; Ergebnisse über Forschungskooperation verfügbar)
## Ergebnisse
| Modell | Accuracy | Precision | Recall | F1-Score |
|-------------------|----------|-----------|--------|----------|
| GPT-4 | 0.89 | 0.30 | 0.74 | 0.43 |
| Gemma 2 | 0.92 | 0.00 | 0.00 | 0.00 |
| Llama 3.1 | 0.84 | 0.22 | 0.69 | 0.33 |
| ClimateBERT-NetZero | -- | -- | -- | -- |
### Interpretation:
- **GPT-4** zeigte die **beste Recall-Leistung** (0.74) und insgesamt eine solide Klassifikationsqualität, auch wenn die Präzision moderat ausfiel – ein typisches Merkmal für generalisierte Modelle bei unscharfen Klassifikationsaufgaben.
- **Gemma 2** erreichte zwar eine hohe Accuracy (0.92), scheiterte jedoch vollständig an der semantischen Erkennung der Zielklasse (Precision/Recall/F1 = 0.00). Dies unterstreicht, dass **Accuracy allein als Metrik irreführend sein kann**.
- **Llama 3.1** schnitt besser ab als Gemma 2 und konnte mit einem Recall von 0.69 relevante Artikel häufiger korrekt erkennen – jedoch mit geringer Präzision.
- **ClimateBERT-NetZero** wurde nicht in die metrische Vergleichstabelle aufgenommen, da es **ausschließlich zur kontextbasierten Vorauswahl relevanter Artikel diente** und **keine Promptanpassung** oder Vergleichbarkeit mit den anderen Modellen möglich war.
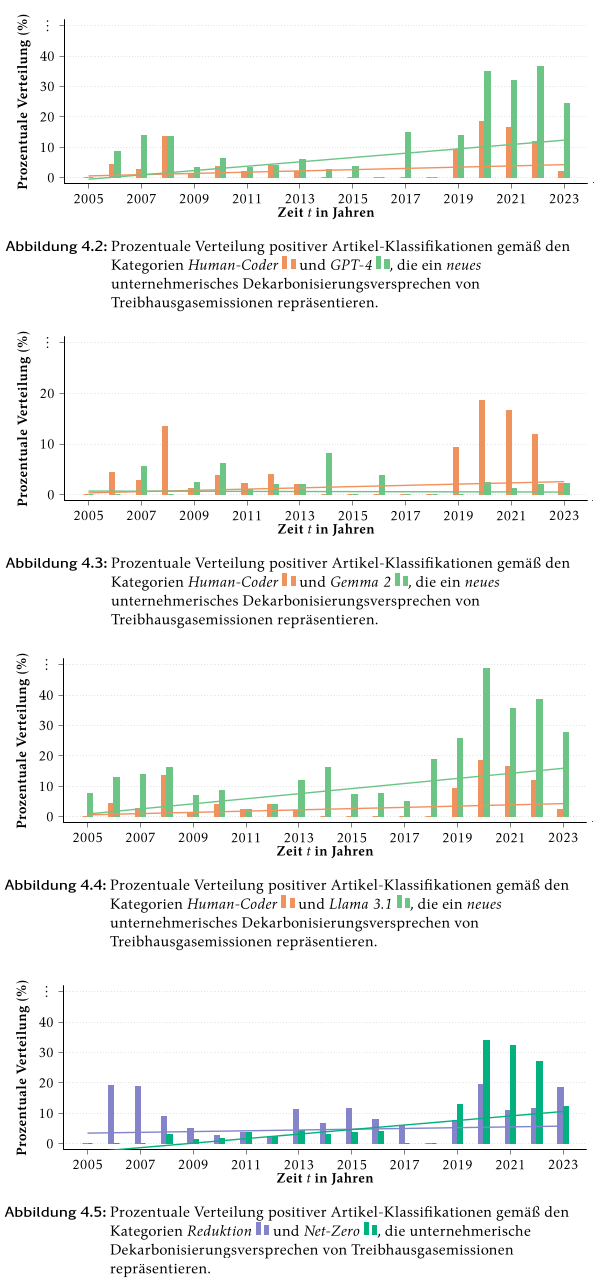
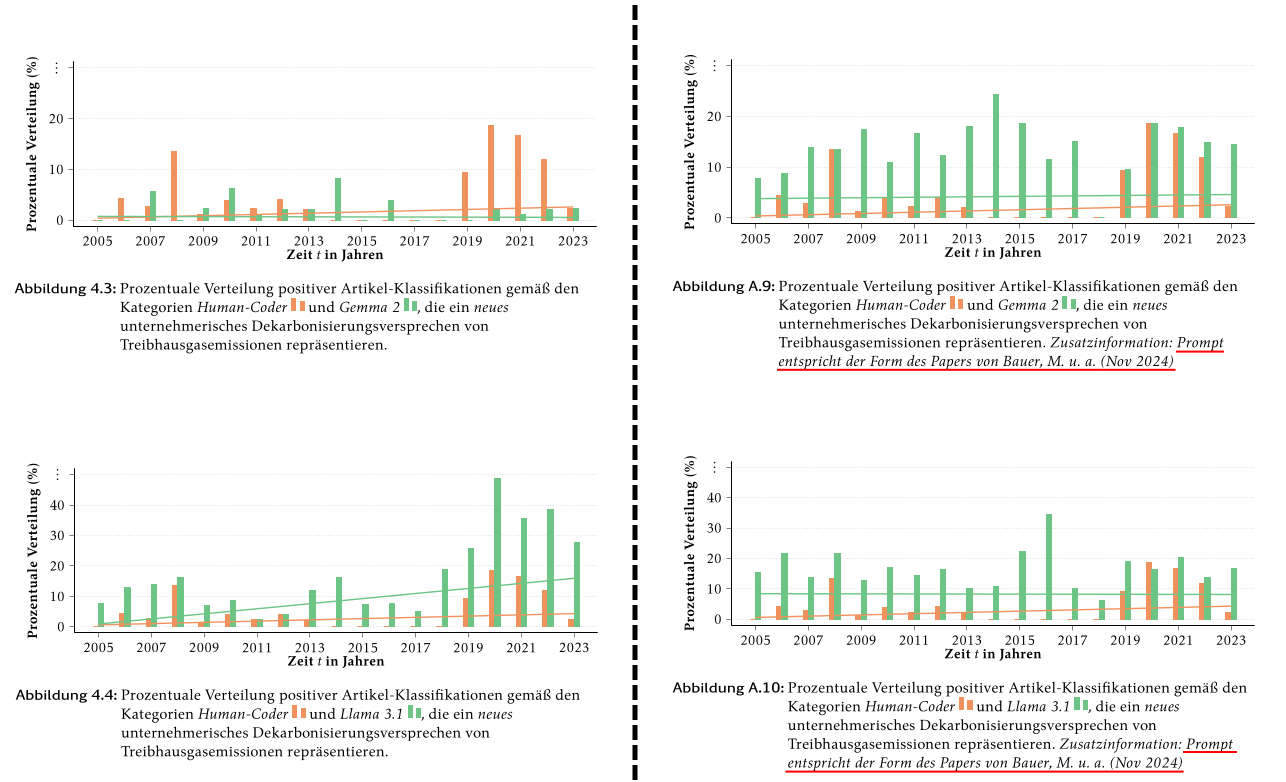
- Ein wesentlicher praktischer Befund dieser Arbeit ist, dass **die Laufzeit des Klassifikationsprozesses bei Gemma 2 und Llama 3.1 ohne angepasste Prompts um den Faktor 1,5 höher lag**. Grund dafür war, dass die Modelle ohne gezielte Prompt-Instruktion häufig ganze generative Textausgaben anstelle der erwarteten **binären Klassifikationen („yes“ / „no“)** zurücklieferten. Erst durch die Einbettung von vier präzisen Klassifikationsbeispielen im Prompt gelang eine stabile Ausgabeform, die zugleich die **semantische Kontexttreue und Modellpräzision erheblich verbesserte**. Besonders deutlich zeigte sich dies bei Gemma 2, das ohne diese Anpassung keinerlei verwertbare Klassifikationsergebnisse lieferte.
## Zielgruppen & Anwendungsfälle
- **Data Scientists & Machine Learning Engineers**, die LLMs im wirtschaftlichen Kontext einsetzen möchten
- **Klimawissenschaftliche Forschung & Policy-Analyse**, für die automatisierte Bewertung von Corporate Pledges relevant ist
- **NLP-Forscher*innen**, die sich mit Prompt-Engineering und LLM-Performance in spezialisierten Domänen befassen
## Persönliches Statement
Diese Arbeit repräsentiert meine Expertise in der Anwendung moderner NLP-Verfahren im Kontext realweltlicher wirtschaftlicher Fragestellungen. Neben einer fundierten Analyse und Evaluierung von LLMs habe ich **praktisch relevante Erkenntnisse zur Promptgestaltung und Modellwahl** abgeleitet, die sich direkt in die Industrie oder weiterführende Forschung übertragen lassen.
---
📬 **Kontakt**:
Marcel Weschke
[LinkedIn](https://www.linkedin.com/in/marcel-weschke-550185147/ "Profile") • marcel.weschke@directbox.de